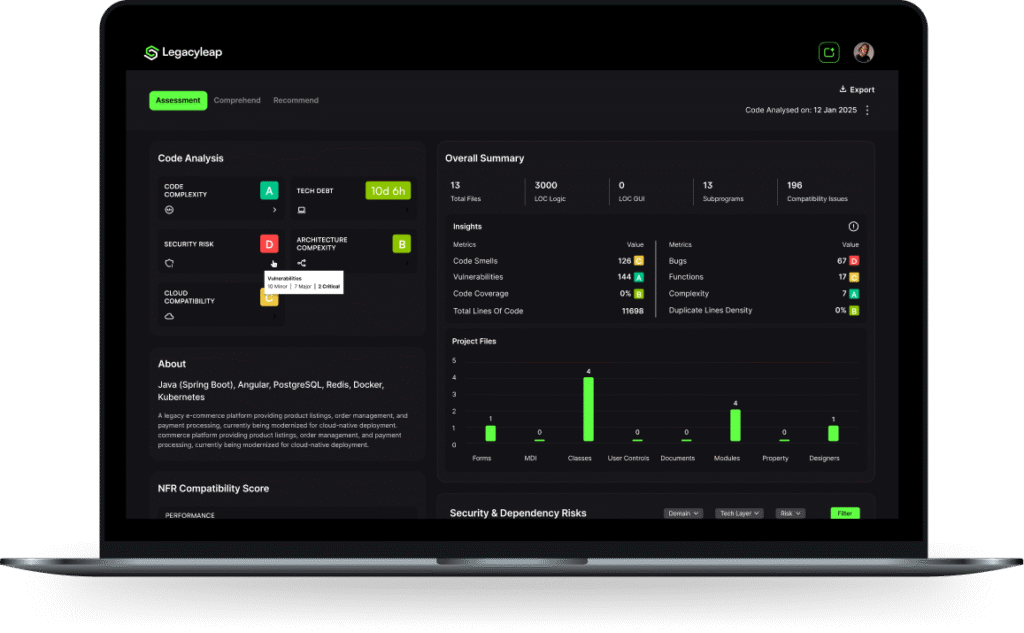
Results at a Glance
| Metric | Result |
| Cost Savings | 55% reduction in total cost of ownership |
| Time-to-Market | 60% faster for new credit products |
| Automation | 80%+ of code transformation automated by Gen AI |
| Scale | 1.5M+ lines of Ab Initio code migrated |
| Data Processing | 50–60% faster post-migration |
| Data Loss | Zero; full business logic preservation |
Engagement Snapshot
| Industry | Financial Services / Credit Scoring |
| Location | Global (primary operations in the US) |
| Legacy Stack | Ab Initio (.mp files, ETL graphs) |
| Target Stack | Apache Spark (Java) + Apache Airflow |
| Scale | 1.5M+ lines of code |
| Delivery Model | Automated migration with Legacyleap’s proprietary parser + IR framework |
About the client:
The client is a global leader in credit scoring, risk management, and data-driven decisioning for financial institutions, lenders, and businesses. Their credit scoring applications and analytics platforms depended on legacy Ab Initio ETL pipelines for creating escalating costs, scalability constraints, and a growing inability to integrate with modern cloud-native platforms.
The client needed a migration path from Ab Initio to a scalable Java Spark architecture without disrupting business-critical credit data pipelines.
Challenge
The client’s Ab Initio environment had reached a tipping point across four compounding constraints:
Vendor Lock-in and Escalating Ab Initio License Costs
Ab Initio licensing fees, hardware maintenance, and the cost of specialized Ab Initio talent were driving total cost of ownership upward with no path to reduction. The proprietary nature of the platform meant every dollar spent deepened the lock-in.
Monolithic ETL Blocking Cloud-Native Integration
The Ab Initio architecture was monolithic and tightly coupled. Complex dependencies between ETL jobs made it difficult to integrate with modern data lakes, cloud-native analytics platforms, or real-time processing frameworks. Modularity, reusability, and horizontal scalability were all blocked.\
Knowledge Drain and Undocumented Transformation Logic
Decades of embedded business logic lived inside Ab Initio transformations with no modern equivalent documentation. Tribal knowledge was the only map, and the people who held it were leaving. Every departure increased the risk of permanent logic loss during any future migration.
Performance Bottlenecks at Modern Data Scale
Legacy ETL jobs could not scale horizontally to handle the velocity, variety, and volume of modern credit data workloads. The inability to leverage distributed processing and cloud-native parallelism created performance ceilings that constrained new product development and analytics delivery.
How Legacyleap Migrated 1.5M Lines of Ab Initio Code
Legacyleap delivered a structured, AI-accelerated migration using its proprietary Ab Initio parser and Intermediate Representation (IR) framework. The engagement followed a clear execution sequence:
Phase 1: Ab Initio Code Parsing and Deep Analysis
Legacyleap’s in-house Ab Initio parser ingested .mp files and dissected complex ETL graphs, business rules, and data transformations. The parser performed detailed analysis of data lineage, metadata, transformation logic, and operational dependencies, capturing the full “as-is” state with complete traceability.
Phase 2: Intermediate Representation (IR) Generation
A vendor-neutral Intermediate Representation was generated as the single source of truth for all downstream activities. The IR abstracted Ab Initio-specific constructs into platform-agnostic transformation metadata, preserving business rules and transformation semantics, data dependencies and control flows, and partitioning and parallelism configurations. No business logic was lost in this abstraction layer.
Phase 3: Assessment and Technical Documentation
Legacyleap auto-generated detailed technical documentation including flow diagrams, data lineage reports, and component-level specifications. A technical debt and complexity assessment highlighted modernization hotspots, and a Transformation Readiness Report estimated migration effort and risk per module. This phase ensured knowledge preservation and simplified all future maintenance.
Phase 4: Automated Code Transformation to Java Spark
Using the IR, Legacyleap’s code generation engine produced optimized Apache Spark code in Java. Advanced Spark patterns (DataFrames, parallelized RDDs, broadcast variables, and window functions) were applied for high performance. Transformations were tuned to leverage distributed computing, cluster parallelism, and in-memory processing for large-scale credit data workloads.
Phase 5: Airflow DAG Orchestration
Legacyleap automated the generation of Apache Airflow DAGs, translating Ab Initio workflows into scalable, modular task orchestration pipelines. Airflow integration enabled seamless scheduling, monitoring, and error handling, and established the foundation for CI/CD automation across the migrated data estate.
Phase 6: Validation and Cloud-Native Optimization
Auto-generated unit tests validated each ETL module against business rules, edge cases, and regression scenarios. Functional parity between Ab Initio and Spark outputs was confirmed across all migrated pipelines. The migrated Spark code was then optimized for cloud-native deployment with auto-scaling, resource tuning, and cost-efficiency strategies, minimizing shuffles, optimizing joins, and improving memory management for maximum throughput.
Data Pipeline Integrity
Data loss is the #1 risk in any ETL migration. Legacyleap addressed this with a layered validation approach:
Every migrated ETL module received auto-generated unit tests covering business rule validations and edge case scenarios. Functional parity testing compared Ab Initio outputs against Spark outputs across all transformation logic and regression scenarios. Data lineage and metadata traceability reports confirmed that no transformation logic was dropped, altered, or orphaned during migration. Airflow DAG monitoring and error handling validated orchestration integrity post-cutover. The result was zero data loss and full business logic preservation across every migrated pipeline.
Quantified Results
| Metric | Before | After | Validation Method |
|---|---|---|---|
| Total Cost of Ownership | Escalating Ab Initio license + hardware + talent costs | 55% reduction | TCO comparison pre/post migration |
| Time-to-Market | Manual ETL development cycles delaying credit product rollouts | 60% faster | Product release timeline comparison |
| Code Transformation | Manual rewrite required for 1.5M+ LOC | 80%+ automated by Gen AI | Automation coverage audit |
| Lines Migrated | 1.5M+ lines locked in Ab Initio | 1.5M+ lines running on Spark | Migration completion report |
| Data Processing Speed | Legacy jobs hitting horizontal scaling ceiling | 50–60% faster | Performance benchmarking pre/post |
| Data Loss | High risk from undocumented logic | Zero; full parity confirmed | Functional parity testing + lineage reports |
| Orchestration | Manual Ab Initio workflow scheduling | Airflow DAGs with CI/CD readiness | DAG monitoring + error handling validation |
Why Not a Manual Rewrite?
Many enterprises consider a manual Ab Initio-to-Spark rewrite before discovering the true cost and risk. Here is how the two approaches compare:
| Manual ETL Rewrite | Legacyleap Automated Migration | |
|---|---|---|
| Timeline | 2–4x longer depending on codebase scale | 60% faster than manual estimate |
| Cost | High – large team of Spark + Ab Initio specialists required for months/years | 55% lower TCO – automation reduces headcount and duration |
| Risk of Logic Loss | High – decades of undocumented business logic must be manually reverse-engineered | Low – proprietary parser + IR framework captures all logic systematically |
| Test Coverage | Often deferred or incomplete due to time pressure | Auto-generated unit tests per ETL module from day one |
| Orchestration | Airflow DAGs must be manually designed and wired | Airflow DAGs auto-generated from Ab Initio workflow definitions |
| Documentation | Must be created manually (often skipped entirely) | Auto-generated flow diagrams, lineage reports, and specs |