LLMs are powerful. But on their own, they’re fragile. Enterprise teams quickly learn this the hard way through hallucinated responses, silent failures, and security gaps no one flagged until it was too late.
To productionize Gen AI, you need more than a model. You need infrastructure built for validation, routing, control, and visibility. Without it, even the best prompts can collapse under unpredictable behavior.
At Legacyleap, we’ve spent the last few months rebuilding our Gen AI pipeline to support production-grade use cases. The result: a new AI Gateway layer designed specifically for enterprise LLM workflows. It’s built on a foundation of:
- TensorZero for unified LLM access, seamless fallback mechanisms, and end-to-end optimization of compound LLM systems
- Guardrails-AI for schema validation and secure prompting
- CodeShield for vulnerability and security assessment of the AI-generated code
- UQLM for measuring uncertainty and surfacing low-confidence outputs
This blog breaks down how we’ve hardened our enterprise Gen AI infrastructure, why this matters, and how it enables faster, safer modernization at scale for you.
This is how we’re moving from LLM experimentation to LLM operations.
Why We Built a New AI Gateway for Our LLM Workflows
Our original LLM setup worked until we had to scale.
Each provider (OpenAI, Claude, Bedrock, etc.) required its own prompt structure, routing logic, and error handling. We had to manually configure retries. Output validation was inconsistent. And every time we switched models, we rewrote the plumbing from scratch.
That worked when things were small. But as we scaled Gen AI across modules like comprehension, code generation, and validation, the fragmentation became a bottleneck.
There were three main issues:
- No unified interface across LLMs. Every model behaved differently.
- No consistent validation. Outputs could silently fail or break downstream logic.
- No fallback or retry routing. If a call failed, we had no graceful recovery.
For internal teams, this slowed development. For enterprise clients, it raised concerns around security, traceability, and LLM observability. We needed a more structured, scalable foundation.
The objective was clear:
- Cut down on glue code
- Improve output reliability
- Build fallback routing across most LLM providers like GPT and Claude, among others
- Enforce enterprise Gen AI validation from the start
That’s what led us to build the AI Gateway. Here’s how we did it.
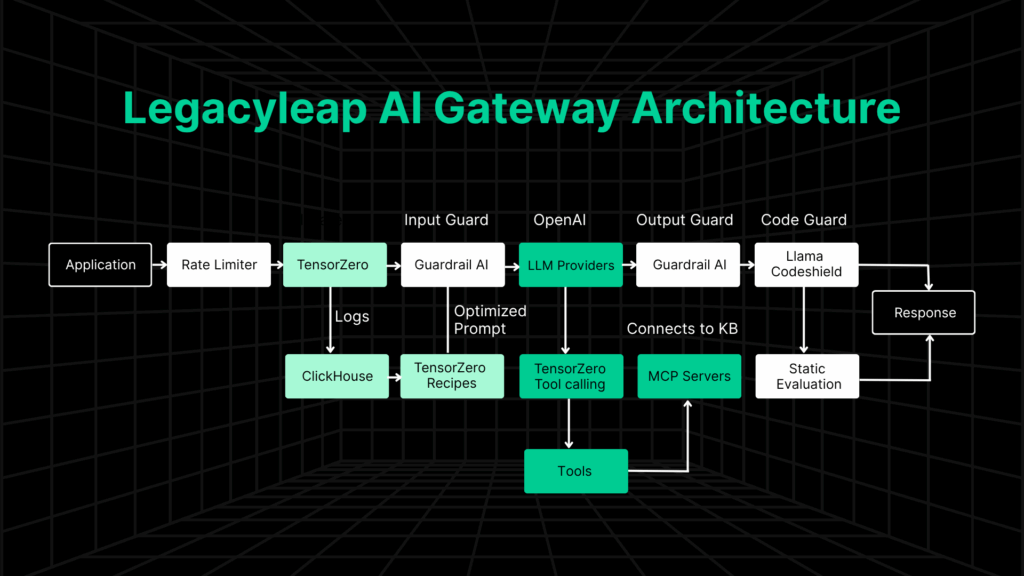
1. Unifying LLM Access and Control with TensorZero
At the center of the AI Gateway is TensorZero, an open-source LLM orchestration layer designed to consolidate and control every part of the inference pipeline.
It acts as a unified API gateway for connecting to any model—OpenAI, Claude, Bedrock, LLaMA, and others—without rewriting logic for each provider. Once configured, we can send structured prompts to multiple LLMs through a single, consistent interface.
Here’s what it enables:
- Model routing and fallback logic with weighted priority and automatic retries
- Batch inference support for running parallel tasks efficiently
- Schema enforcement to guarantee predictable, structured outputs
- ClickHouse logging for querying inferences, retries, and failure rates at speed
- Feedback capture, including demonstrations and ratings, to improve prompt quality
- A/B testing across models, prompts, and configurations
- Recipes to automate prompt optimization and dataset generation over time
TensorZero also supports multi-step workflows (called “episodes”), allowing us to break down complex interactions and apply feedback at each stage. That granularity gives us more control over where things break and how to fix them.
Since implementing it, we’ve seen a 40–60% increase in output stability and retry success, with clearer metrics around where models fail and why.
This is what turns experimentation into infrastructure and gives us the LLM observability tools needed to operate reliably at scale.
2. Validating Inputs and Outputs with Guardrails-AI
Once an LLM produces a response, you still need to ask: Is this safe? Is this usable? Can I trust it downstream?
That’s where Guardrails-AI fits in.
Sitting on top of the inference layer, Guardrails acts as a structured validation and safety filter, automatically checking both inputs and outputs before anything reaches your application logic.
Here’s what it covers:
- Output validation against strict schemas (JSON, XML, or custom regex)
- Prompt injection detection, including jailbreak attempts hidden inside document payloads
- Content filtering to block unsafe or policy-violating responses
- Retry logic for malformed or invalid outputs
- PII detection for emails, contact info, and sensitive identifiers
- Context-aware filtering to reduce false positives (e.g., distinguishing between security alerts vs. threats)
This structured inference validation ensures that LLM responses are formatted, safe, and production-ready.
Guardrails also supports retries by default. If a model fails validation, it auto-retries with the same prompt and schema until a valid response is returned or routes the request through a fallback.
With Guardrails-AI in place, we’ve significantly reduced silent failures and unstructured outputs, laying the groundwork for real LLM output validation at enterprise scale.
Read this if you want to learn more about how Gen AI helps build unbreakable safety nets for modernization.
3. Securing Code Generation with LLAMA CodeShield
AI-generated code can accelerate modernization. That’s both powerful and risky.
When Gen AI is used to refactor legacy logic or scaffold new modules, it’s critical to validate what gets written. Poorly structured output or unsafe patterns can create security gaps that are easy to miss in fast-moving pipelines.
To prevent that, we integrated LLAMA CodeShield, an MIT-licensed module from the LlamaPack ecosystem, directly into our inference stack.
CodeShield evaluates each generated output for:
- Known vulnerabilities
- Unsafe command execution
- Interpreter abuse and escape attempts
It runs at inference time and acts as a filter before code is passed into downstream systems or exposed to users.
This gives us a structured approach to AI-generated code safety, ensuring outputs meet basic security expectations before review. In high-trust workflows, it’s now a required part of our secure code generation LLM architecture.
Want to learn more about how Legacyleap uses Gen AI to analyze and understand legacy code? Read this: How To Achieve Full Legacy System Comprehension with Gen AI.
4. Closing the Feedback Loop with Observability and Recipes
You can’t improve what you don’t track. That’s why every inference in our pipeline is logged and audited through ClickHouse, giving us real-time visibility into model performance across workflows.
Each entry includes:
- Model and provider used
- Prompt and output
- Retry and fallback history
- Error codes and failure reasons
- Response time and token usage
- Output structure compliance
This layer of AI observability gives our teams the ability to debug faster, detect patterns, and validate whether changes actually improve outcomes.
On top of this, we use prompt optimization workflows powered by TensorZero Recipes. These pipelines analyze inference logs, identify underperforming prompts, and auto-generate variants for testing. As the dataset grows, it becomes easier to fine-tune prompts (or entire models) based on real usage.
We’ve also integrated UQLM (Uncertainty Quantification for Language Models) into the loop. This scores the confidence of each output, flagging low-certainty responses for further review or rerouting.
For high-impact workflows, every model output is routed through a mandatory HITL (Human-in-the-loop) checkpoint where expert reviewers validate functional accuracy, schema adherence, and domain-specific correctness before acceptance. Their feedback becomes part of the dataset, improving future accuracy.
This feedback loop is the engine behind continuous improvement across all LLM-powered workflows.
5. Putting Safety Nets in Place: Fallbacks, Retries, and Limits
Production workloads can break in unpredictable ways. The difference is how you recover.
In our AI Gateway, every inference passes through a resilience layer designed to catch failures, reroute requests, and maintain stability without manual intervention.
Key controls include:
- Weighted fallback routing across providers (e.g., OpenAI → Claude → Bedrock), based on availability and confidence
- Built-in retry logic for transient failures, schema mismatches, or timeouts
- Token usage tracking at the module level, so we know exactly what each service consumes
- Rate limiting for external users, with configurable caps (e.g., 50K tokens/user/month) to control cost exposure
These safety nets give us predictable behavior under load, fewer hard failures, and better visibility into how different models perform under real-world pressure.
The result is a resilient inference layer built to recover gracefully, minimize disruption, and surface detailed logs across every fallback, retry, and rate-limited request.
If you want to zoom in on how Legacyleap builds resilience into Gen AI workflows, read this article: Secure AI-Driven Application Modernization: Your 2026 Blueprint.
What This Means for Legacyleap Customers
If you’re using Legacyleap to modernize legacy applications, the AI Gateway upgrade directly improves how your transformations run, scale, and stay safe.
Here’s what changes for you:
- Modernization pipelines are more stable. Prompt outputs are validated, schema-checked, and retried automatically, reducing fragility during comprehension and transformation
- Code generation is safer by design. Every block of LLM-generated code is scanned for vulnerabilities before it enters your system
- LLM decisions are traceable. You can audit which model was used, how it responded, and why fallback was triggered
- Compliance risks are mitigated early. PII filters, prompt injection detection, and contextual safeguards are applied before inference ever reaches downstream logic
- Your usage is observable. Token consumption, retries, and model performance can be monitored per module, per user
- HITL is wired into the workflow. For high-impact modules, a reviewer validates accuracy and safety before outputs are accepted
- You now have a clear path to agentic automation with tool-calling, SDK integrations, and dynamic workflows becoming part of your modernization toolkit
This is a direct investment in the reliability, security, and enterprise readiness of every application Legacyleap helps you modernize.
Future-Proofing Gen AI Modernization with Safe, Scalable Foundations
The new AI Gateway now defines how Gen AI operates inside Legacyleap, from validation and fallback to auditability and control.
It’s built to be the foundation for:
- Agentic workflows that involve multiple model calls, tools, and human review
- Internal knowledge utilities that depend on structured outputs and context-aware filtering
- System-level orchestration, where Gen AI integrates cleanly with enterprise data and logic
Everything is modular, observable, and production-ready. From day one, it’s been designed to handle scale without sacrificing safety or performance.
This is the foundation for how Legacyleap will continue delivering modernization: secure by default, transparent by design, and extensible for what’s next.
If you’re exploring Gen AI-driven modernization, we’re offering a $0 assessment to evaluate your current stack, highlight refactoring opportunities, and map what a transition could look like.
FAQs
An AI Gateway is an infrastructure layer that manages how enterprise systems interact with LLMs. It handles schema validation, routing, fallback logic, and safety enforcement, turning Gen AI from an experimental tool into a production-grade service.
Legacyleap uses Guardrails-AI to validate outputs, detect prompt injection, and apply contextual filters. Insecure code is filtered using LLAMA CodeShield, while UQLM flags low-confidence outputs. Every high-impact workflow is reviewed through a human-in-the-loop checkpoint.
TensorZero acts as the orchestration engine for Legacyleap’s AI Gateway. It provides a unified API to connect with multiple LLM providers, enforces structured inputs and outputs, routes fallback calls, logs every inference, and powers optimization workflows like A/B testing and prompt recipes. It’s the central layer that turns GenAI from model calls into operational infrastructure.
Every inference, successful or failed, is logged in ClickHouse with details like model used, retries triggered, response latency, and token usage. This enables teams to trace behavior, debug failures, and optimize prompt performance across the full GenAI pipeline.
Yes. The AI Gateway was built with agentic use cases in mind, supporting multi-step reasoning, tool use, context-aware routing, and human-in-the-loop checkpoints. It forms the foundation for SDK integrations, orchestration, and autonomous LLM-based agents.